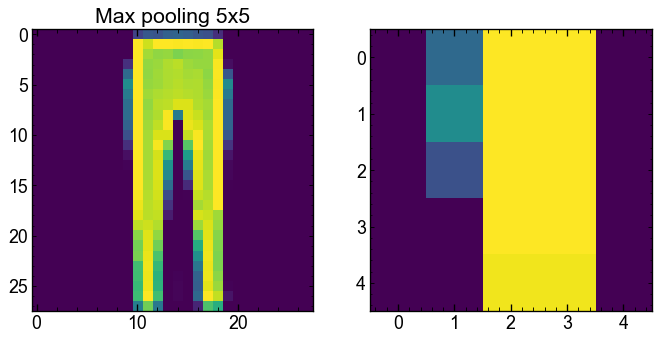
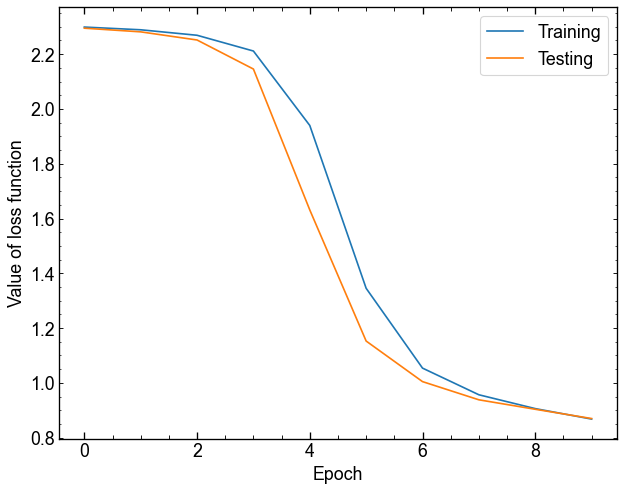
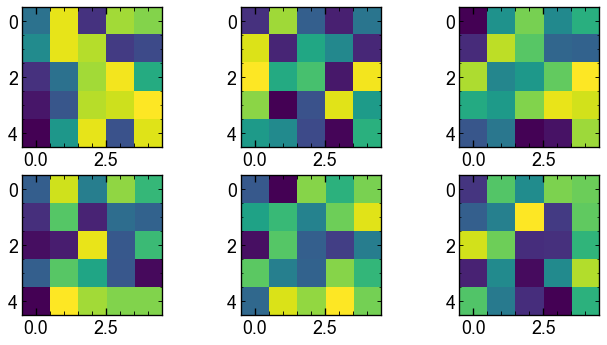
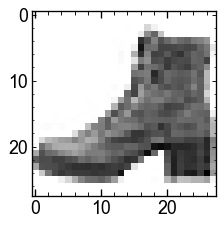
[('weight', Parameter containing:
tensor([[[[ 0.0800, -0.1799, 0.1703, 0.0339, 0.0554],
[ 0.1457, -0.0275, -0.0277, 0.0035, 0.1321],
[ 0.0712, 0.1540, -0.0917, -0.0476, 0.0065],
[-0.1241, -0.0134, 0.1495, 0.1670, -0.1185],
[-0.1769, -0.1931, -0.0075, 0.1401, -0.1695]]],
[[[-0.0206, 0.0617, 0.0442, -0.0014, 0.1138],
[-0.1092, 0.0176, -0.0281, 0.1778, 0.1826],
[ 0.1960, 0.0975, 0.1572, -0.1681, -0.0474],
[-0.0475, 0.1754, 0.1790, -0.1781, -0.1130],
[ 0.0893, -0.1466, -0.0501, -0.1676, 0.1343]]],
[[[ 0.0216, -0.0785, -0.1971, -0.1649, -0.0032],
[ 0.0031, 0.1500, -0.1767, 0.1741, 0.1568],
[-0.1509, -0.0530, -0.1620, -0.1160, 0.1937],
[-0.0961, -0.1331, 0.1240, -0.0296, 0.0672],
[ 0.1318, -0.0978, -0.0728, -0.1708, 0.1805]]],
[[[-0.1671, 0.1997, -0.0913, 0.1932, -0.0567],
[ 0.0721, -0.1631, -0.1789, 0.0435, 0.1031],
[ 0.1298, 0.1166, -0.1382, -0.0744, -0.0193],
[ 0.1365, -0.0076, 0.1346, 0.0506, -0.1966],
[ 0.1280, -0.0168, 0.1350, -0.0929, -0.0801]]],
[[[ 0.0840, -0.1920, 0.1901, 0.0113, -0.1135],
[-0.1310, -0.1826, 0.0063, 0.0530, -0.0703],
[ 0.0842, -0.0203, -0.0168, -0.0468, 0.1402],
[-0.0471, -0.0189, -0.0891, 0.1796, 0.1657],
[ 0.1137, 0.0260, -0.0080, -0.1797, -0.0683]]],
[[[-0.0622, -0.0399, -0.0988, 0.0381, -0.1632],
[-0.0959, -0.0428, -0.0317, -0.0406, -0.0424],
[-0.1168, 0.0839, 0.1199, 0.1339, 0.0627],
[-0.1939, 0.1510, 0.1900, -0.1863, -0.0432],
[ 0.1819, 0.0476, -0.0623, -0.1550, -0.0849]]],
[[[-0.1485, 0.0029, -0.1731, -0.0747, 0.0735],
[ 0.0471, 0.0101, -0.0025, 0.0216, -0.0031],
[-0.1680, -0.0091, -0.0933, 0.1536, -0.0615],
[-0.0452, 0.1725, -0.1230, -0.1961, 0.0412],
[ 0.1769, -0.1849, 0.0610, 0.0793, 0.0560]]],
[[[-0.0504, -0.0807, 0.0611, -0.1317, 0.1000],
[-0.0762, -0.0077, -0.0289, -0.0673, 0.0227],
[ 0.0154, -0.1720, -0.0623, 0.1830, -0.1550],
[-0.0271, 0.0212, -0.0894, 0.0092, 0.0615],
[-0.1106, 0.0723, -0.0537, 0.1342, -0.0223]]]], requires_grad=True)), ('bias', Parameter containing:
tensor([-0.1509, 0.1085, -0.0060, 0.1042, 0.0565, 0.0512, 0.1428, 0.1578],
requires_grad=True))]