INFO 04-Dec-2309:02:03: Default options to initialize R: rpy2, --quiet, embedded.py:20 --no-save
INFO 04-Dec-2309:02:03: R is already initialized. No need to initialize. embedded.py:269
Code
catalog = load_catalog()
[12/04/23 09:02:04] WARNING /Users/zijin/miniforge3/envs/cool_planet/lib/python3.10/site-packages/kelogger.py:205dro_datasets/polars/lazy_polars_dataset.py:14: KedroDeprecationWarning: 'AbstractVersionedDataSet' has been renamed to 'AbstractVersionedDataset', and the alias will be removed in Kedro 0.19.0 from kedro.io.core import (
INFO Loading data from 'THB.STATE.inter_data_sw'(LazyPolarsDataset)...data_catalog.py:502
Code
all_ds = [JNO_ds, Wind_ds, STA_ds, THB_sw_ds]
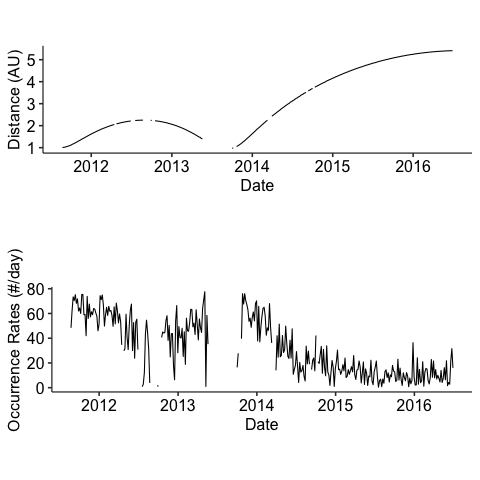
Distance and Occurrence rates versus time for JUNO
Code
def calc_or_df(events: pl.DataFrame, avg_window: timedelta, by=None):"""Calculate the occurence rate of the candidates with the average window. Notes: occurence rate is defined as the number of candidates per day. """ every = avg_window or_factor = every / timedelta(days=1)return ( events.sort("time") .group_by_dynamic("time", every=every, by=by) .agg( cs.float().mean(), o_rates=pl.count() / or_factor ) .upsample("time", every=every) # upsample to fill the missing time )
%%Rp1 <- ggplot(df, aes(x = time, y = radial_distance)) + geom_line() +# Plot distance by date labs(x ="Date", y ="Distance (AU)") + theme_pubr(base_size =16) + theme(aspect.ratio=0.25)p2 <- ggplot(df, aes(x = time, y = o_rates)) + geom_line() +# Plot distance by date labs(x ="Date", y ="Occurrence Rates (#/day)") + theme_pubr(base_size =16) + theme(aspect.ratio=0.25)p <- ggarrange(p1, p2, nrow =2)# save_plot("distance_and_or")p
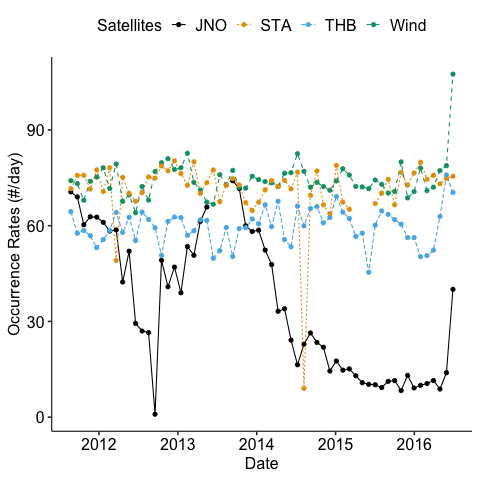
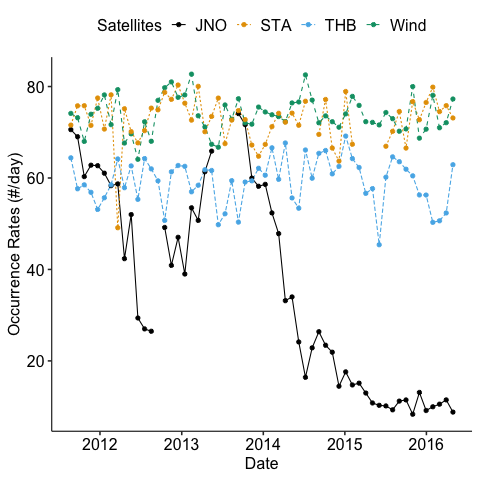
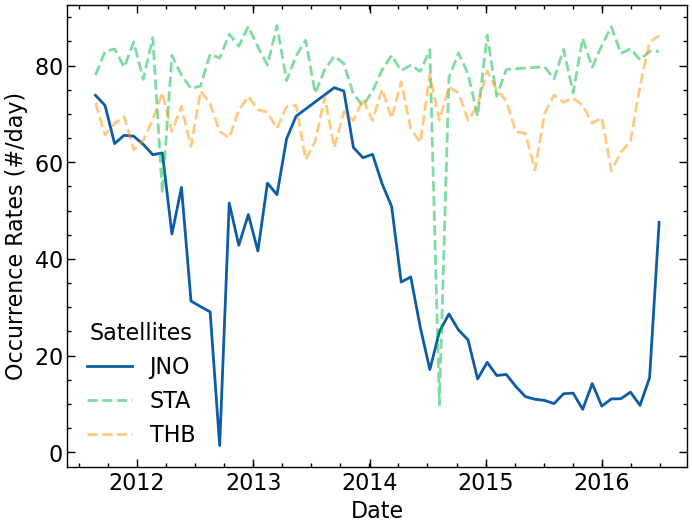
Occurrence rates versus time for all missions
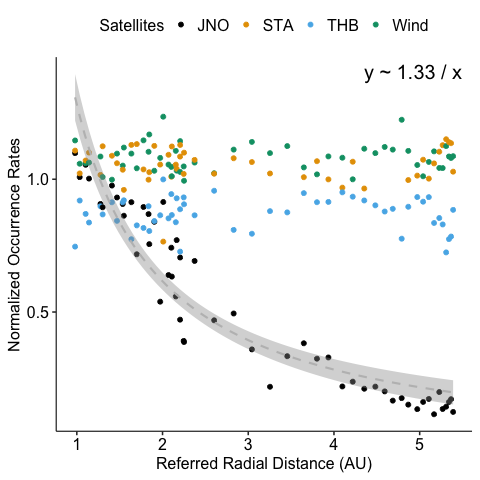
Data normalization
Different levels of normalization are applied to the data. The normalization is done in the following order:
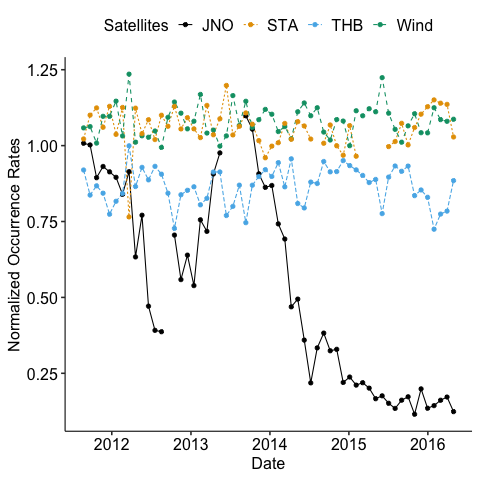
N1: normalize the data by the the effective time of every duration due to the data gap as we may miss some potential IDs. We assume the data gap is independent of the magnetic discontinuities.
N2: normalize the data by the mean value of data near 1 AU. This is to remove the effect of the temporal variation of the solar wind.
Code
def calc_n1_factor( data: pl.LazyFrame, s_resolution: timedelta, l_resolution: timedelta,):return ( data.sort("time") .group_by_dynamic("time", every=s_resolution) .agg(pl.lit(1).alias("availablity")) .group_by_dynamic("time", every=l_resolution) .agg(n1_factor=pl.sum("availablity") * s_resolution / l_resolution) )def n1_normalize( df: pl.DataFrame, # the dataframe with count to be normalized data: pl.LazyFrame, # the data used to calculate the duration ratio s_resolution, # the smallest resolution to check if the data is available avg_window,): duration_df = calc_n1_factor(data, s_resolution, avg_window).with_columns( cs.datetime().dt.cast_time_unit("ns"), )return df.lazy().join(duration_df, how="left", on="time").with_columns( o_rates_normalized=pl.col("o_rates") / pl.col("n1_factor") ).collect()@patchdef calc_or_normalized(self: cIDsDataset, s_resolution: timedelta, avg_window: timedelta): count_df = calc_or_df(self.candidates, avg_window)return n1_normalize(count_df, self.data, s_resolution, avg_window)
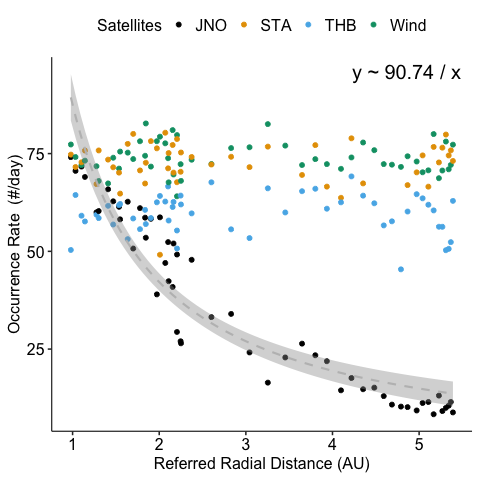
We noticed some anomalies in the occurrence rates of the magnetic discontinuities for Stereo-A data. Also for Juno, its occurrence rate is much higher when approaching Jupiter.
Surprisingly, we found out that the anomaly of STEREO-A data is not mainly due to data gap. We can inspect this data further. See appendix.
We remove the intervals which do not have enough data points to calculate the normalized occurrence rates accurately and restrict the time range to exclude Jupiter’s effect.
Notes: seaborn.lineplot drops nans from the DataFrame before plotting, this is not desired…
Code
import seaborn as snsimport matplotlib.pyplot as pltimport scienceplotsfrom discontinuitypy.utils.plot import savefig
Code
plt.style.use(['science', 'nature', 'notebook'])
Code
def plot_or_r(df: pl.DataFrame):"plot normalized occurence rate over radial distance" sns.lineplot(x="ref_radial_distance", y="o_rates_normalized", hue="sat", data=df) ax = plt.gca() # Get current axis ax.set_yscale("log") ax.set_xlabel("Referred Radial Distance (AU)") ax.set_ylabel("Normalized Occurrence Rate")# savefig('occurrence_rate_ratio')return ax.figure
Code
def plot_or_time(df: pl.DataFrame):"""Plot the occurence rate of the candidates with time. """# Create a unique list of all satellites and sort them to let JNO' be plotted first all_sats = df["sat"].unique().to_list() all_sats.sort(key=lambda x: x !="JNO")# Plot each satellite separatelyfor sat in all_sats: sat_df = df.filter(sat=sat)if sat =="JNO": sns.lineplot(sat_df, x="time", y="o_rates_normalized", label=sat)else:# Making the other satellites more distinct with linestyle and alpha sns.lineplot( sat_df, x="time", y="o_rates_normalized", linestyle="--", # dashed line style alpha=0.5, # keep the order of the legend label=sat, ) ax = plt.gca() # Get current axis# Set the y-axis and x-axis labels ax.set_ylabel("Occurrence Rates (#/day)") ax.set_xlabel("Date") ax.legend(title="Satellites")# savefig("occurrence_rates")return ax.figure
import plotly.graph_objects as go;from plotly_resampler import FigureResamplerimport plotly.express as px
Code
# px.line(mag, x='time', y='B') # This is extremely slow for large datasetsfig = FigureResampler(go.Figure())fig.add_trace({"x": mag["time"], "y": mag['B']})fig